SPIDER!
前不久才刚刚初步学习了爬虫相关知识,跟随教程简单爬取了医院和招聘网站的信息,没想到在美赛实现了如此规模(170万字)的爬虫!!Spider haunts at night!!
题目

Illegal wildlife trade negatively impacts our environment and threatens global biodiversity. It is
estimated to involve up to 26.5 billion US dollars per year and is considered to be the fourth
largest of all global illegal trades.
[1] You are to develop a data-driven 5-year project designed to make a notable reduction in illegal wildlife trade. Your goal is to convince a client to carry out your project. To do this, you must select both a client and an appropriate project for that client.
Your work should explore the following sub-questions:
● Who is your client? What can that client realistically do? (In other words, your client should have the powers, resources, and interest needed to enact the project you propose.)
● Explain why the project you developed is suitable for this client. What research, from published literature and from your own analyses, supports the selection of your proposed project? Using a data-driven analysis, how will you convince your client that this is a project they should undertake?
● What additional powers and resources will your client need to carry out the project? (Remember to use assumptions, but also ground your work in reality as much as you are able.)
● If the project is carried out what will happen? In other words, what will the measurable impact on illegal wildlife trade be? What analysis did you do to determine this?
● How likely is the project to reach the expected goal? Also, based on a contextualized sensitivity analysis, are there conditions or events that may disproportionately aid or harm the project’s ability to reach its goal?
While you could limit your approach to illegal wildlife trade, you may also consider illegal wildlife trade as part of a larger complex system. Specifically, you could consider how other global efforts in other domains, e.g., efforts to curtail other forms of trafficking or efforts to reduce climate change coupled with efforts to curtail illegal wildlife trade, may be part of a complex system. This may create synergistic opportunities for unexpected actors in this domain.
If you choose to leverage a complexity framework in your solution, be sure to justify your choice by discussing the benefits and drawbacks of this modeling decision.Additionally, your team must submit a 1-page memo with key points for your client, highlighting your 5-year project proposal and why the project is right for them as a client (e.g., access to resources, part of their mandate, aligns with their mission statement, etc.)
目标
经过一番国际层面的研究,我们把最终的客户锁定在中国。于是,找到中国非法贸易的数据并分析成为了目标,可以从非法贸易的审判书等资料获取。
Spider!
导入所需的库
1 | from bs4 import BeautifulSoup |
定位
1 | driver = webdriver.Edge() |
1 | page_url = f'{base_url}{search_url}{1}.shtml' |
1 | last_page_link = soup.find('a', text='尾页') |
到这里,我们可以实现对搜索内容相关的每一页,每一篇文章进行遍历
爬取
1 | from docx import Document |
完工!
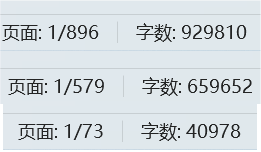
170万字 1400+篇文章!!!